
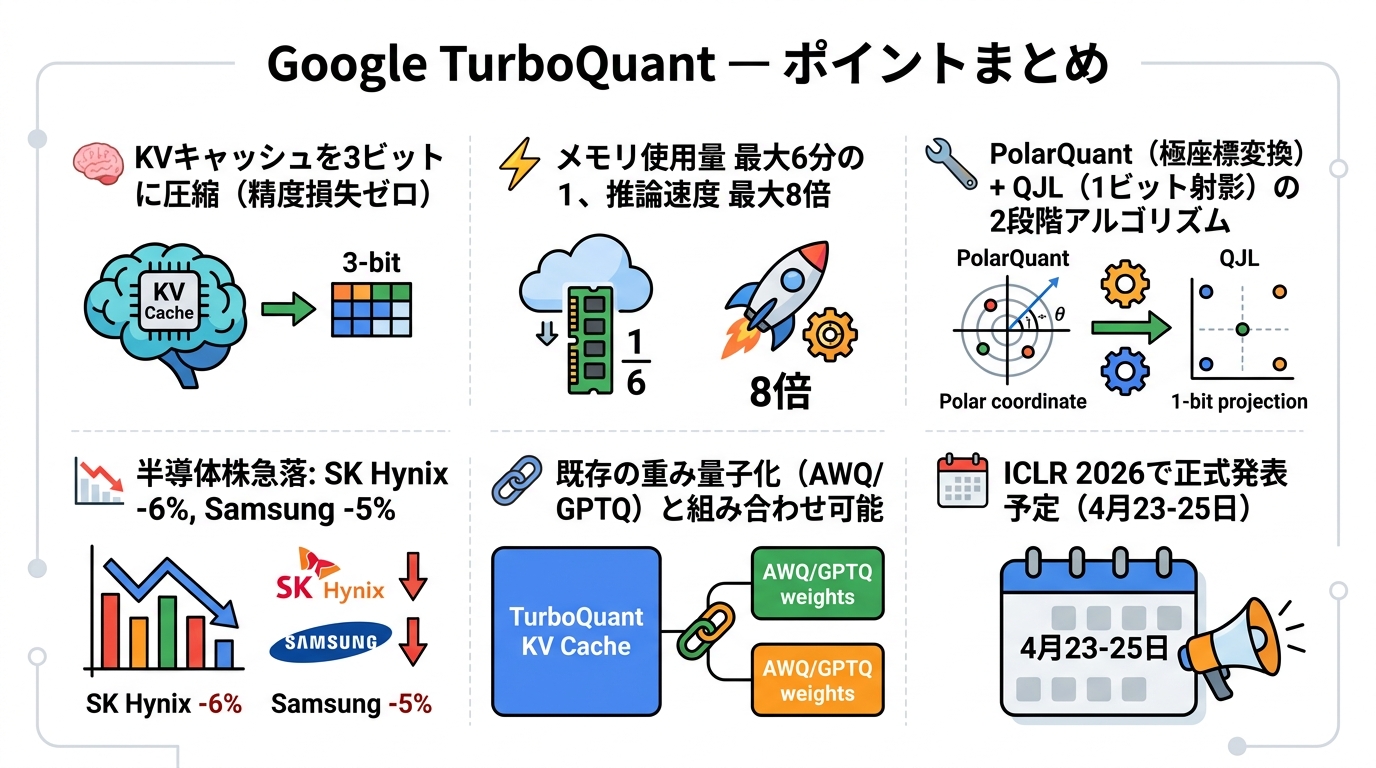
GoogleのTurboQuant、KVキャッシュを3ビットに圧縮——精度ゼロ損失でメモリ6分の1、推論8倍速
Google Researchが2026年3月25日に発表した新アルゴリズム「TurboQuant」が、AI推論インフラの前提を根底から覆しつつある。LLMのKVキャッシュを3〜4ビットに圧縮しながら精度を一切損なわない。ファインチューニングも不要。そのインパクトは論文の枠を超え、翌日にはメモリチップ市場を直撃した。
KVキャッシュとは何か、なぜ問題なのか
LLMが長い文脈を処理するとき、過去のトークンに対応するKey・Valueベクトルをメモリに蓄積し続ける。これがKVキャッシュだ。文脈長が伸びるにつれてキャッシュサイズは線形に膨らみ、128Kトークンを扱うモデルでは数十GBに達することも珍しくない。
従来の量子化手法——GPTQ、AWQ、GGUFなど——は「モデルの重み」を圧縮する技術だ。いわば教科書のサイズを小さくすること。一方でKVキャッシュは「会話のメモ帳」に相当し、推論が走るたびにリアルタイムで肥大化する。TurboQuantはこの「メモ帳」の問題に正面から向き合った。率直に言えば、重み量子化とKVキャッシュ圧縮は解くべき問題がそもそも異なる。
PolarQuantとQJL——2段階の数学的アプローチ
TurboQuantの核心は、PolarQuantとQJL(Quantized Johnson-Lindenstrauss)という2つのアルゴリズムの組み合わせにある。
PolarQuantはデータベクトルをデカルト座標から極座標に変換し、「大きさ(半径)」と「方向(角度群)」に分離する。角度分布の偏りが予測可能であることを利用し、従来手法で必須だったブロック単位の正規化ステップを省略できる。これが計算オーバーヘッドを最小化する鍵だ。
QJLはJohnson-Lindenstrauss変換を応用し、高次元データを低次元に射影する際、各成分を符号ビット(+1または−1)の1ビットに落とし込む。高精度なクエリと低精度なデータを組み合わせる特殊な推定量が、内積の歪みを統計的に補正する仕組みだ。ここが気になるところで、「なぜ1ビットに落としても精度が保てるのか」という問いに対する答えが、Johnson-Lindenstrauss補題の確率論的な保証にある。
ベンチマーク結果——数字が示す実力
H100 GPUでの実測値は次の通りだ。
- KVキャッシュのメモリ使用量:16ビット比で最大6分の1に削減
- アテンション計算の推論スループット:最大8倍向上
- 精度の低下:LongBench、Needle In A Haystack等のベンチマークでゼロ
Llama-3.1-8BおよびMistral-7Bでの検証では、非圧縮モデルとほぼ同一のリコールスコアを記録している。4ビット時の8倍速というのは4ビット換算での数値で、3ビットではさらにメモリ効率が高まる。
既存手法との比較でも際立つ。AWQが約95%、GGUFが約92%、GPTQが約90%の精度保持率であるのに対し、TurboQuantはKVキャッシュ圧縮において理論上・実測上とも損失ゼロを主張している。加えて、TurboQuantはGPTQ/AWQと競合しない。重みはAWQで圧縮し、KVキャッシュはTurboQuantで圧縮する——この組み合わせが最も効果的な構成になりうる。
メモリチップ市場への衝撃
発表翌日の3月26日、半導体市場は即座に反応した。SK Hynixが約6%下落、Samsungが約5%下落、KioxiaとSandiskも同様に下げ、MicronもUS市場で大きく売られた。KOSPIは3%超の下落となり、半導体銘柄が指数全体を引きずる展開となった。
投資家の論理は単純だ。AIモデルが6分の1のメモリで動作するなら、データセンターで必要とされるHBMの発注量が激減する——そう読んだわけだ。ただ、アナリストの多くは「短期的な過剰反応」と評価している。TurboQuantが最適化するのはあくまでも推論時のKVキャッシュだ。モデルの学習フェーズでは依然として大量のHBMが必要であり、そちらの需要は影響を受けない。
NVIDIA、そしてエコシステムへの波及
個人的には、TurboQuantの「隠れた受益者」がNVIDIAである点が興味深い。メモリ効率が6倍になるということは、同じH100で6倍の並行セッション、あるいは6倍の文脈長を処理できる。これまでコスト面で導入を躊躇していたユースケースにGPUが入り込む余地が生まれ、むしろGPU需要の裾野が広がる可能性がある。
公式のオープンソースリリースはICLR 2026(2026年4月23〜25日)の前後を予定しており、llama.cppへの統合も活発に議論されている。Googleは本アルゴリズムをCloud TPU環境に優先統合するとみられ、Google Cloud上でのLLM推論コストが大幅に下がる可能性が高い。
「研究フェーズ」から「インフラの常識」へ
TurboQuantは現時点でまだ研究論文の段階だ。本番環境での大規模検証はこれからで、エッジケースや特定モデルアーキテクチャでの挙動はまだ未知数の部分も残る。それでも「ファインチューニング不要」「既存モデルにそのまま適用可能」という特性は、実用化への障壁を著しく低くしている。
KVキャッシュの爆発的な肥大化は、長文脈AIの普及を阻む最大のボトルネックの一つだった。それを精度ゼロ損失で解決する手法が登場したことは、推論コストの構造を変える出来事として記憶されることになるだろう。メモリチップ株の反応が「頭の痛い問題」を可視化した、とも言える。
Sources:
- TurboQuant: Redefining AI efficiency with extreme compression | Google Research Blog
- Google's TurboQuant reduces AI LLM cache memory capacity requirements by at least six times | Tom's Hardware
- A Google AI breakthrough is pressuring memory chip stocks from Samsung to Micron | CNBC
- Decoding Google's TurboQuant: 6x KV Cache Cut — Headwind for Memory Players? | TrendForce
- TurboQuant - Extreme KV Cache Quantization | llama.cpp Discussion