
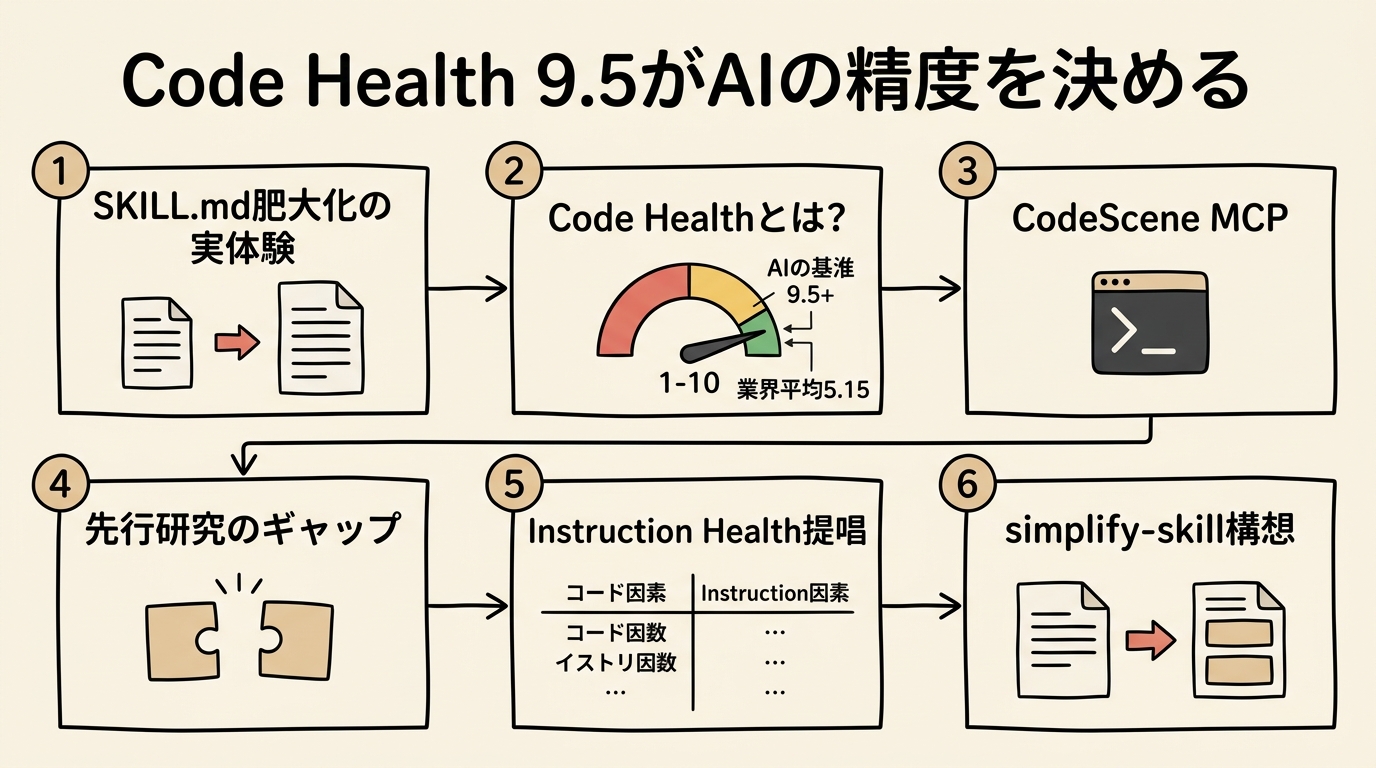
第2回:Code Health 9.5がAIの精度を決める——ソースコードからプロンプトまで品質を測る
シリーズ: バイブコーディングの実態(全3回)
開発ワークフローを全自動化するSkillを作りました。最初は200行程度だったはずが、環境ごとの分岐、エラーハンドリング、テンプレートを足していくうちに1270行まで膨らみました。
ステップを飛ばす。テンプレートを混同する。同じ指示に対して毎回異なる解釈をする。「これはAIの性能の問題か、それとも指示の品質の問題か」という問いが頭から離れなくなりました。組織設計用に作ったSkillも775行。どちらも「動く」が、AIに渡すには少し重すぎます。
前回の記事では、AIコードの品質問題をデータで検証しました——CodeRabbitの調査によるAIコードの1.7倍の問題密度、Politowskiらが示した「アンチパターン2つで正答率44%」という崩壊の閾値。今回は視点を変えて、「指示する側」の品質に目を向けます。
Code Healthという基準 — CodeSceneが25年かけて定量化したもの
CodeSceneは25以上の要因を組み合わせた複合スコア「Code Health」を1〜10のスケールで算出します。単一の指標ではなく、モジュール・関数・実装のそれぞれのレイヤーにまたがる問題を統合した数値です。

各要因の例を挙げると、Low CohesionやBrain Class(モジュールレベル)、Complex MethodやNested Complexity(関数レベル)、DRY ViolationsやPrimitive Obsession(実装レベル)といった分類になります。人間基準では9.0以上がGreen(健全)、4.0〜8.9がYellow(技術的負債あり)、1.0〜3.9がRed(深刻)とされています。
AI向けの基準はさらに厳しいです。ホワイトペーパーV2が提示するのは9.5以上です。
なぜ0.5の差が大きいか。CodeSceneの研究チームが2026年のFORGE査読済み論文(Borg et al.)で5,000のPythonリポジトリを6種類のLLMで分析したところ、健全なコードと不健全なコードの間で全LLMにわたって有意な相関が確認されました。具体的にはClaude Sonnetで健全なコードの欠陥率3.81%に対し、不健全なコードでは5.19%。Gemmaでは最大15.12ポイントのリスク削減効果がありました。
さらに長期データが示す数字は鮮明です。Code Redの研究によれば、Code Healthが高いプロジェクトでは欠陥が最大15分の1、開発速度が最大9倍になります。IT業界全体の平均は5.15。大半のプロジェクトが、そもそもAIを有効活用できる状態にありません。
ひとつ留保を加えておきます。論文が比較対象としているのはCode Health 7.0以上のコードです。真に不健全なコード(4以下)での挙動は未測定であり、実際のリスクはさらに高い可能性があります。
Claude Codeから直接計測する — CodeScene MCP
CodeScene MCPサーバーがOSSとして公開されており、Claude Codeからワンコマンドで追加できます。
claude mcp add codescene -- npx @codescene/codehealth-mcp
提供されるツールは code_health_review、pre_commit_code_health_safeguard、analyze_change_set など。変更前後のCode Healthを追跡し、リファクタリングの優先度を機械的に判断できます。料金は月額€8(約1,300円)で30日間の無料トライアルがあります。ソースコードはローカル処理のみなのでプライバシー面の懸念もありません。
効果の数字も出ています。MCP搭載環境でのExtract Method実行回数は7,550件から21,702件へ約2.9倍に増加し、Code Health改善量は通常の2〜5倍という報告があります。トークン消費についても、健全なコードベースで約50%削減という副次効果が確認されています。AIに渡すコードが整理されていると、無駄な文脈が減ります。当たり前の話ですが、数字で見せられると腑に落ちます。
先行研究の整理 — プロンプトの品質は測れるか
ここで少し立ち止まって、既存の研究が何をカバーしているかを確認します。
Prompt Debt(arxiv 2509.20497)はプロンプトにおける技術的負債の概念です。短期的な修正の積み重ねが保守負担を増大させるメカニズムを理論化しています。「なぜ指示が劣化するか」の原因論として機能します。同論文が定義するPrompt SmellsとRequirement Smellsは、コードスメルのプロンプト版です。品質を損なうパターンを分類したものとして有用です。
Prompt Alignment(DeepEval)は出力が指示に準拠しているかを測る指標で、「AIが正しく答えたかどうか」を評価します。Prompt Hygieneは定性的なベストプラクティス集で、プロンプトを清潔に保つ10のルールを示しています。
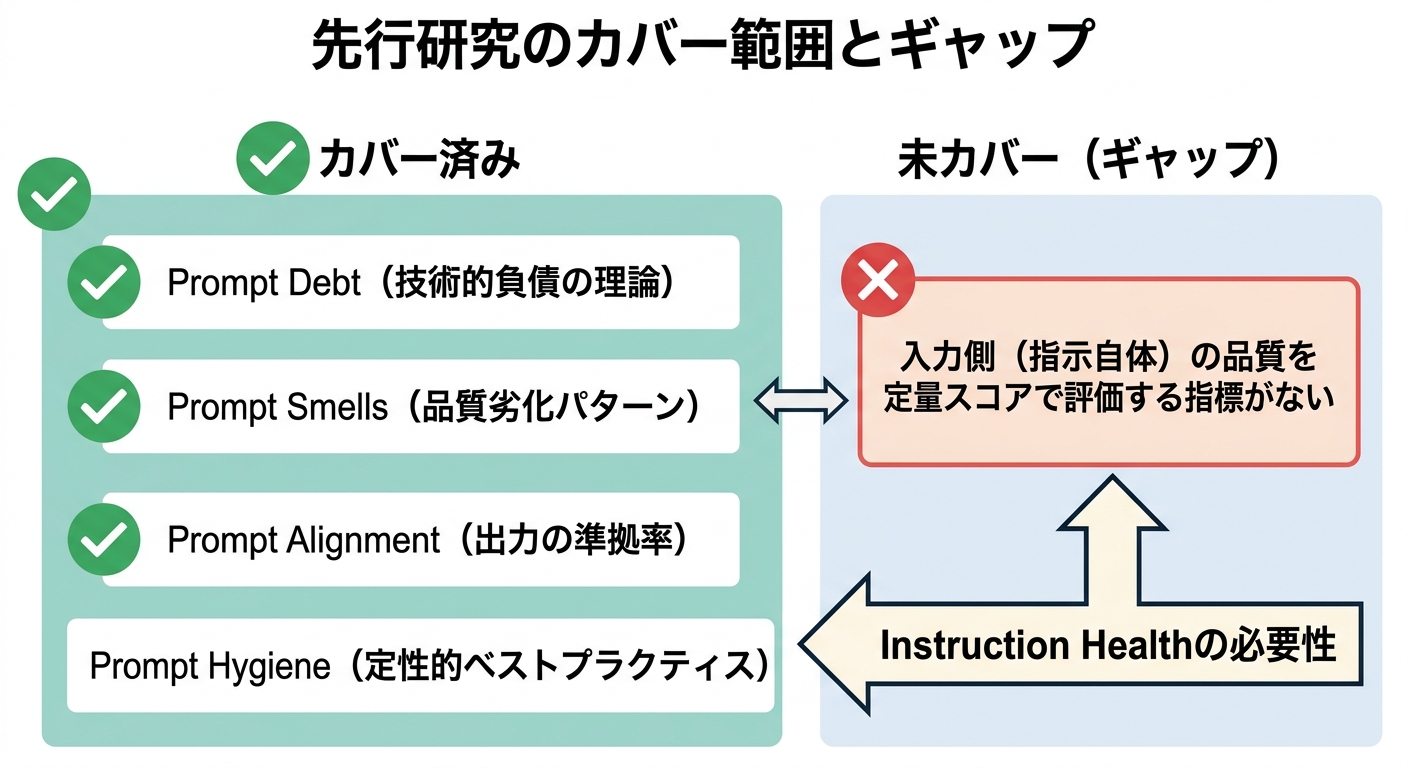
これらを並べると、共通のギャップが見えてきます。「入力側(指示自体)の品質を、定量スコアで評価する枠組み」が存在しないことです。Prompt Debtは「なぜ劣化するか」を説明しますが、「今の指示は何点か」とは言いません。Prompt Alignmentは「出力がどれだけ正確か」を測りますが、「入力の設計品質」は対象外です。
Instruction Health — 提唱
前置きが長くなりました。ここがこの記事の核心です。
この概念はオリジナルの提唱であり、上述の先行研究を踏まえた上で筆者が名付けたものです。Code Healthの方法論を参考にした独自指標として、LLMへの指示(SKILL.md、CLAUDE.md、Rules、system prompt)の品質を定量スコアで評価する試みを「Instruction Health」と呼びます。
ひとつ正直に述べておきます。Code Healthが25年の研究蓄積と5,000リポジトリの実証データに裏打ちされた指標であるのに対し、Instruction Healthは筆者が設定した6要因と重み付けに基づく独自指標です。学術的な検証は行われておらず、スコアの絶対値にCode Healthほどの意味はありません。意味があるのは相対値(Before/After) です。計測→改善→再計測のループが回るかどうか、つまり「改善の方向性を示すコンパス」としての機能が本質になります。
Code Healthの各要因にはInstruction Healthの対応物があります。
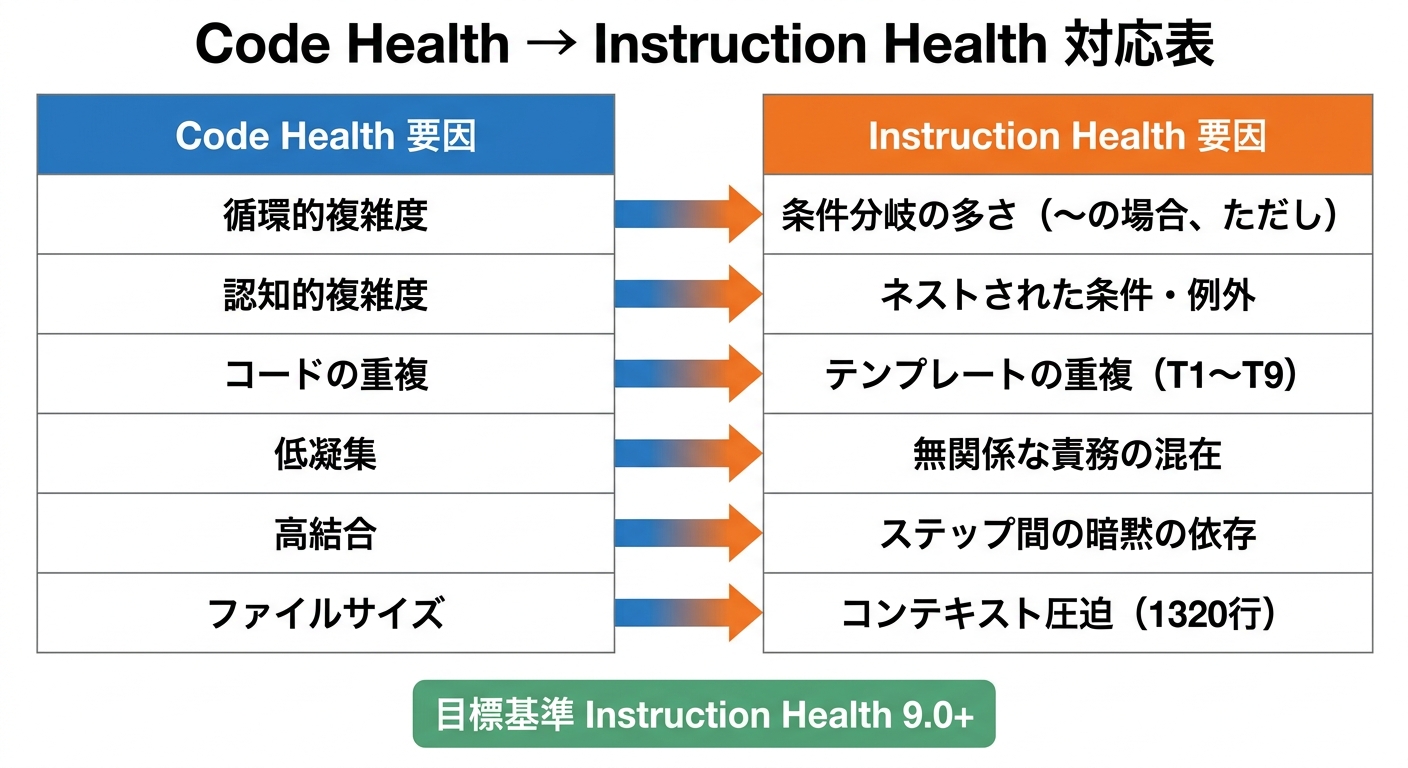
循環的複雑度に対応するのは「条件分岐の多さ」——「〜の場合」「ただし」「〜を除く」が連鎖するほど、AIが正確に実行できるパスが減ります。認知的複雑度はネストされた条件・例外の深さに対応します。コードの重複はテンプレートの重複として現れ、環境別の似たようなテンプレートが微妙な差分でコピペされている状態がその典型例です。低凝集は1つのSKILL.mdに環境構築とテスト実行とデプロイ手順が詰め込まれている状態、高結合は前ステップの結果を明示せず暗黙的に参照している状態と読み替えられます。ファイルサイズはコンテキスト圧迫に直結します。
実例で言うと、筆者が開発した組織設計Skill(775行)は感覚的に「6〜7くらいかな」と見積もっていました。ところが後述するツールで実測したところ5.4。開発ワークフロー基盤Skill(1270行)に至っては3.8でした。感覚はあてにならない、という事実を、自分自身のSkillで思い知ることになりました。
目標基準はCode Health 9.5に倣い、Instruction Health 9.0以上を理想基準として設定します。ソースコードより0.5低くしたのは、指示が持つ意図的な曖昧さや文脈依存性がコードとは性質が違うからです。ただし後述するように、複雑なインタラクティブSkillでは8.0台が現実的なラインです。重要なのは数字そのものより、計測→改善のループが回ることにあります。
Instruction Healthを計測するツール — 実測結果
CodeScene MCPでソースコードのCode Healthを計測できるなら、同じ発想でInstruction Healthも計測できるのではないか。そう考えて、SKILL.md・CLAUDE.md・Rulesを対象にInstruction Healthスコアを算出するClaude Code Skill「instruction-health」を開発しました。ただしCode HealthがCodeSceneの確定的なアルゴリズムで算出されるのに対し、こちらはLLMによる分析なので、実行ごとにスコアがブレる可能性があります。
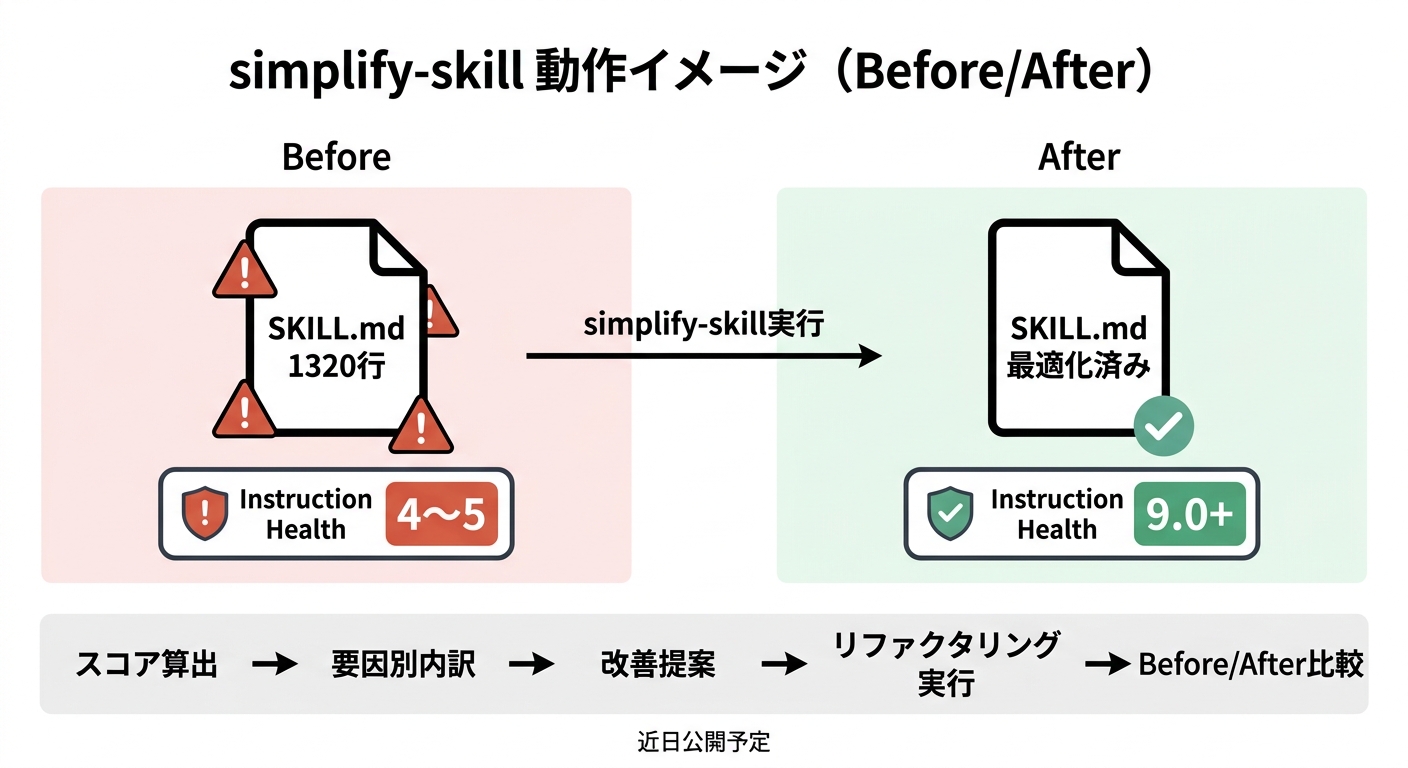
6要因(条件分岐・認知的複雑度・責務の凝集度・サイズ効率・テンプレート重複・依存の明示性)を加重平均で算出し、改善提案→リファクタリング→Before/After比較まで一気通貫で実行します。
実際に筆者のSkillで計測→改善した結果がこちらです。
| Skill | Before行数 | Beforeスコア | After行数 | Afterスコア | 改善幅 |
|---|---|---|---|---|---|
| 組織設計Skill | 775行 | 5.4(危険) | 196行(4ファイル分割) | 8.2(要改善) | +2.8 |
| 開発WF基盤Skill | 1270行 | 3.8(危険) | 197行(3ファイル分割) | 8.4(要改善) | +4.6 |
いずれも9.0には届いていません。複雑なインタラクティブSkill(ヒアリング→分岐→生成)は、責務を分割しても条件分岐が一定数残るため、9.0到達は簡単ではありませんでした。一方で、シンプルなCLAUDE.mdやRulesファイルであれば9.0+は十分に達成可能です。
それでも+2.8、+4.6という改善幅は一貫しており、「計測→改善→再計測」のループが確実に回ることは実証できました。
まとめ — 筆者の所感
「AIの精度はAIの性能で決まる」という見方は半分しか正しくありません。
Code Healthの研究が示したのは、AIに渡す素材(コード)の品質が出力に直接影響するという事実です。それをさらに一段広げれば、AIに渡す指示の品質もまた出力に影響します。自明のようで、定量的な言語で語られることがなかった領域です。
Code Health 9.5は研究に裏打ちされた基準です。Instruction Health 9.0は研究的根拠のない独自基準です。この2つを同列に語ることはできません。しかし「設計がないとだめ」「指示が長すぎる」という定性的な感覚に、数字で方向性を示すコンパスを与えられたことには意味があると考えています。
筆者自身、775行のSkillを「6〜7くらいだろう」と見積もっていたのが実測5.4でした。感覚のズレこそが、計測ツールの存在意義を裏付けています。9.0を全てのファイルで達成するのは現実的ではないかもしれません。しかし「計測して、改善して、再計測する」ループが回る状態を作ったことに、このシリーズの価値があると考えています。
シリーズ全3回
- 第1回:バイブコーディングとコード品質の実態
- 第2回:Code Health 9.5がAIの精度を決める(この記事)
- 第3回:CodeScene MCP × refactor-health 実践ガイド(近日公開)
関連記事
Sources
- AI-Ready Code: How Code Health Determines AI Performance (Whitepaper V2) | CodeScene
- Code for Machines, Not Just Humans (FORGE 2026) | Borg et al. / arXiv
- Making Legacy Code AI-Ready: Benchmarks on Agentic Refactoring | CodeScene
- PromptDebt: A Comprehensive Study of Technical Debt Across LLM Projects | arXiv
- CodeScene MCP Server | GitHub
- Prompt Alignment Metric | DeepEval