
第1回:バイブコーディングとコード品質の実態——1.7倍の問題、2つ重なれば正答率44%
シリーズ: バイブコーディングの実態(全3回)
バイブコーディングには独特の「高揚感」があります。AIに意図を伝え、数十行のコードが瞬時に生成される。動く。テストも通る。「速い」という実感が積み重なって、そのスタイルが定着していきます。
ところが、数週間後に同じコードを開くと様相が変わります。何を意図したか思い出せない関数、どこから呼ばれているかわからないグローバル変数、似たような処理が3か所にコピーされたロジック。バイブコーディングの「速度」については別稿で分析しました。この記事では"品質"に焦点を当てます。
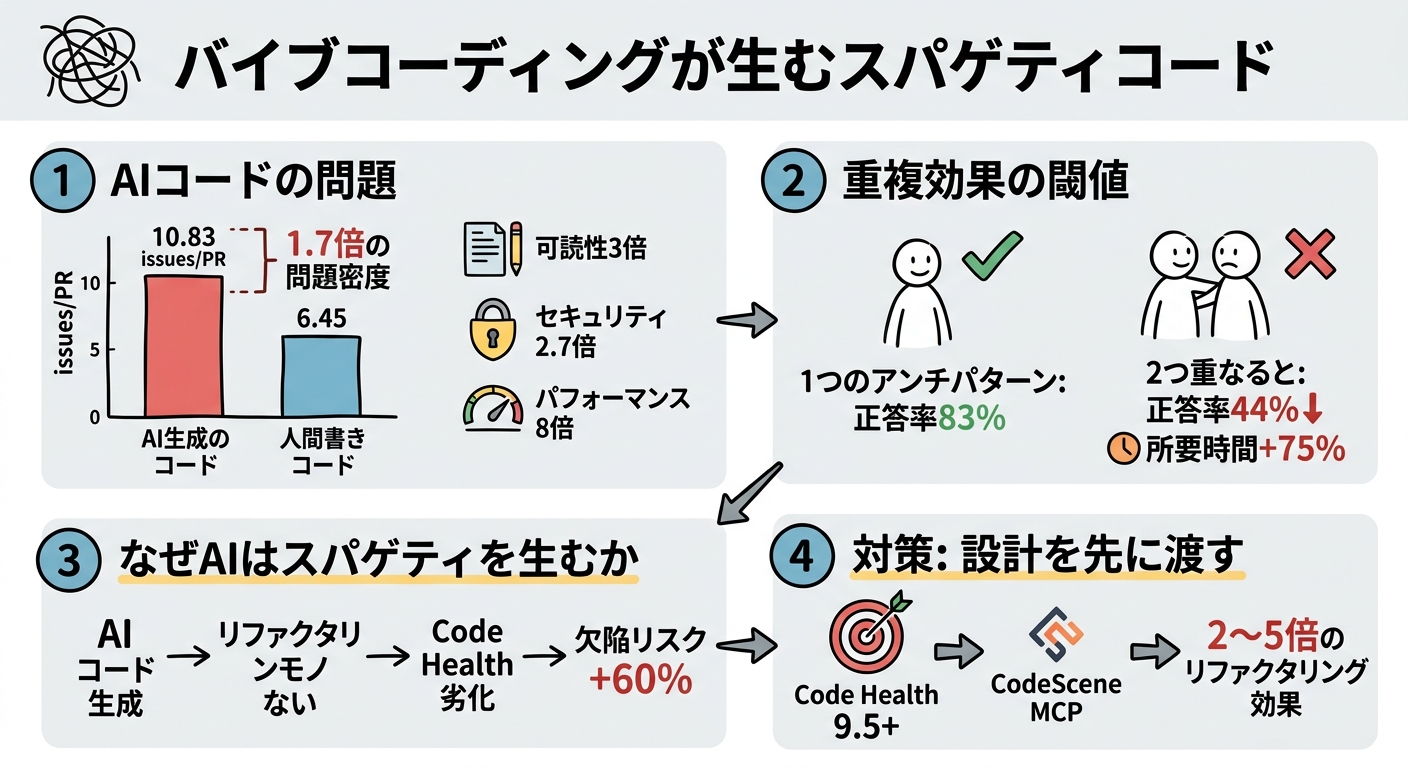
AIコードは人間の1.7倍の問題を含む
CodeRabbitが2024年12月に発表した調査は、AI共著コードと人間が書いたコードを直接比較した数少ないデータセットの一つです。対象はGitHub上の470件のプルリクエスト(AI共著320件、人間のみ150件)。
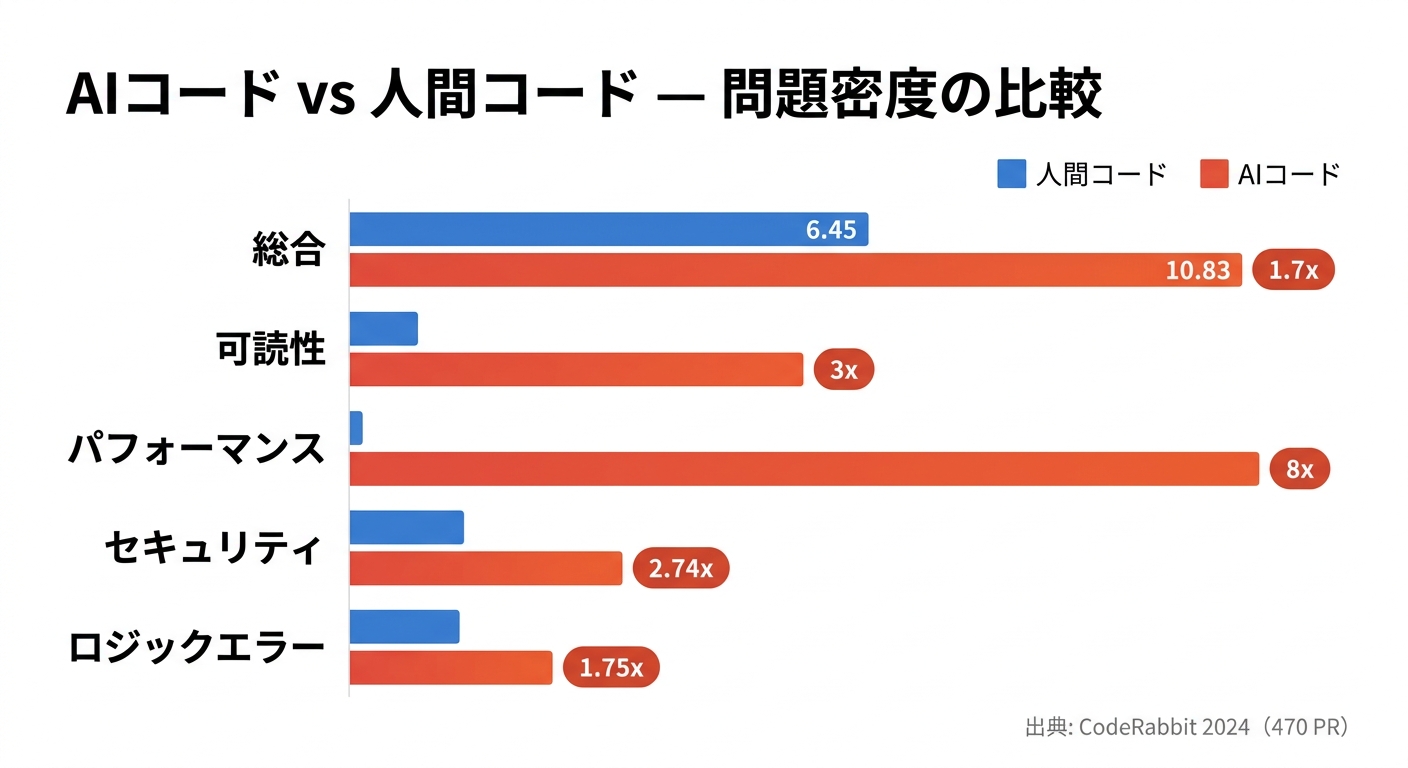
結果は率直です。AI共著PRには1件あたり平均10.83の問題が検出されたのに対し、人間のみのPRは6.45。1.7倍の差があります。問題の種類別に見ると、差はさらに鮮明になります。可読性問題は3倍以上、パフォーマンス非効率(過剰なI/O操作を含む)は8倍、セキュリティ問題は2.74倍、フォーマット問題は2.66倍、命名の一貫性は約2倍、ロジックエラーも75%増でした。
ひとつ留保を付けておきます。CodeRabbitはAIコードレビューツールのベンダーであり、「AIコードに問題が多い」という調査結果は同社の製品価値と方向性が一致しています。利益相反の可能性は否定できません。その上で、GitClearが別途公表した2025年のデータも同じ傾向を指しています。コードのクローン率が8.3%から12.3%に上昇し、リファクタリング行動は25%から10%以下に減少しました。複数の独立したデータが同じ方向を向いている点は無視しにくいです。
「1つなら耐えられるが、2つ重なると破綻する」
数字が大きくなるほど実感が薄れます。ここで学術研究が別の角度からコード品質問題を照らしてくれます。
Politowski らが2020年に発表した研究(カナダ・イタリアの大学、被験者133名、372タスク)は、スパゲティコードが人間の理解能力に与える影響を定量的に測定しました。スパゲティコードの定義にはDECOR手法を用い、長いメソッド、パラメータのない関数、グローバル変数の多用、オブジェクト指向設計の欠如といった特徴でコードを分類しています。
結果の中で最も印象に残るのは「重複効果」です。アンチパターンが1つだけ存在する場合、タスクの正答率や所要時間に統計的に有意な差は出ませんでした(p > 0.05)。ところが2つのアンチパターンが重なった途端に状況が一変します。正答率は83%から44%に下落し、所要時間は107秒から187秒へ75%増加しました。効果量はCohen's d = 1.20〜1.61、これは「大規模効果」に分類される数値です。
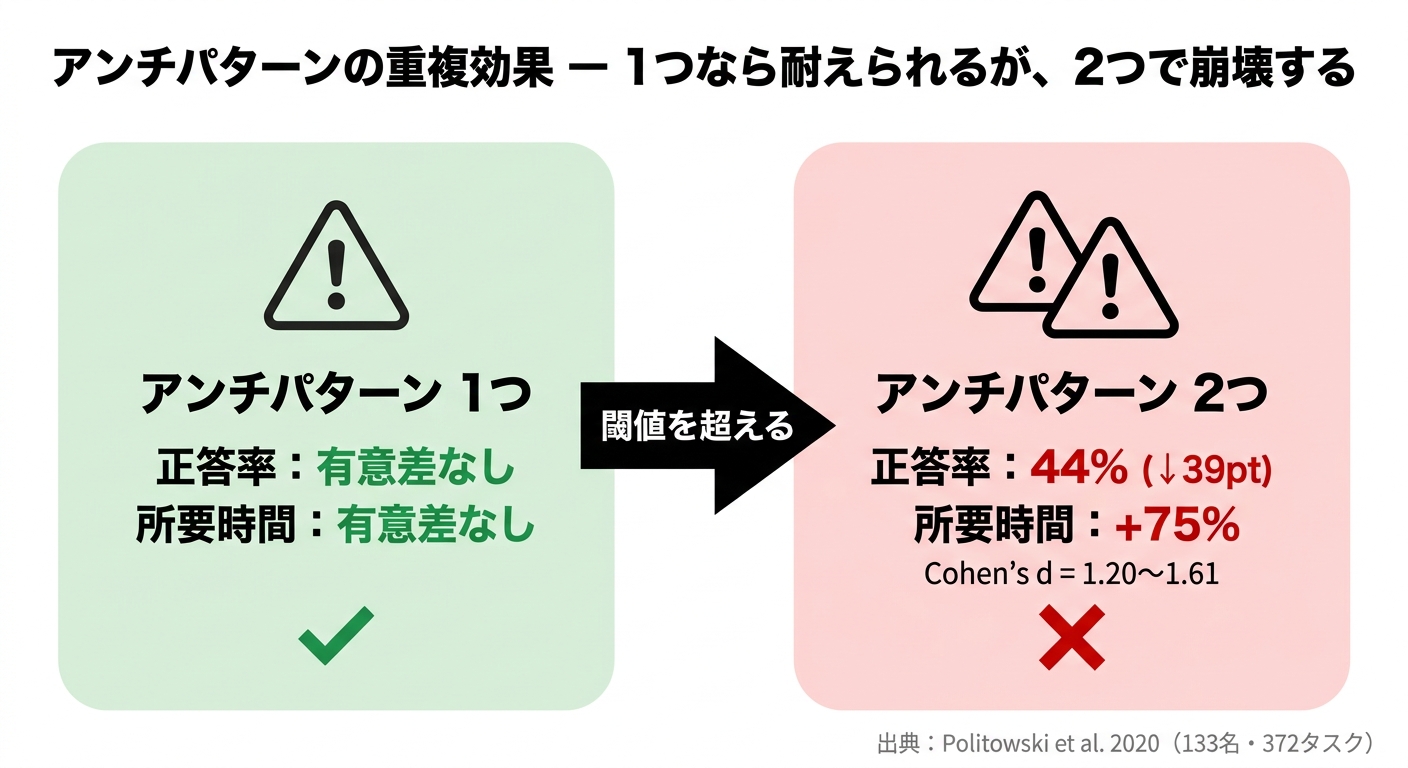
人間のコード理解には閾値がある、という話です。ある程度の乱雑さは吸収できます。ただ複数の問題が重なると、それを補う認知的余裕がなくなります。
ここでバイブコーディングと接続したいです。AIは個々のファイルを「動くコード」として出力します。しかし1回の生成で長いメソッドと命名の不統一が同時に混入することは珍しくありません。それが次の生成で別のファイルに伝播し、さらに別の問題と重なります。チーム全体として見れば、複数のアンチパターンが積み重なった状態がデフォルトになっていきます。Politowskiらの研究が示す「2つの重複で理解能力が崩壊する」という現象が、プロジェクト規模で起きるわけです。
なぜAIはスパゲティを生むのか
構造的な原因を整理しておきます。
AIは「動くコード」を最適化しますが、「保守しやすいコード」を最適化していません。プロンプトに「リファクタリングしやすく書いて」と明示しない限り、AIが自発的に「このコードは整理すべき」と判断することはありません。Bram Cohenが指摘したように、AIは問われたことに答えますが、問われていない設計上の問題を指摘しようとはしません。
GitClearのデータが示すリファクタリング行動の急減(25%→10%以下)も同じ構造を反映しています。AIがコードを生成するたびにリファクタリングの機会が生まれますが、「AIが書いてくれたコード」を人間が積極的に整理しようという動機は働きにくいです。コピーされたコードが残り続けます。
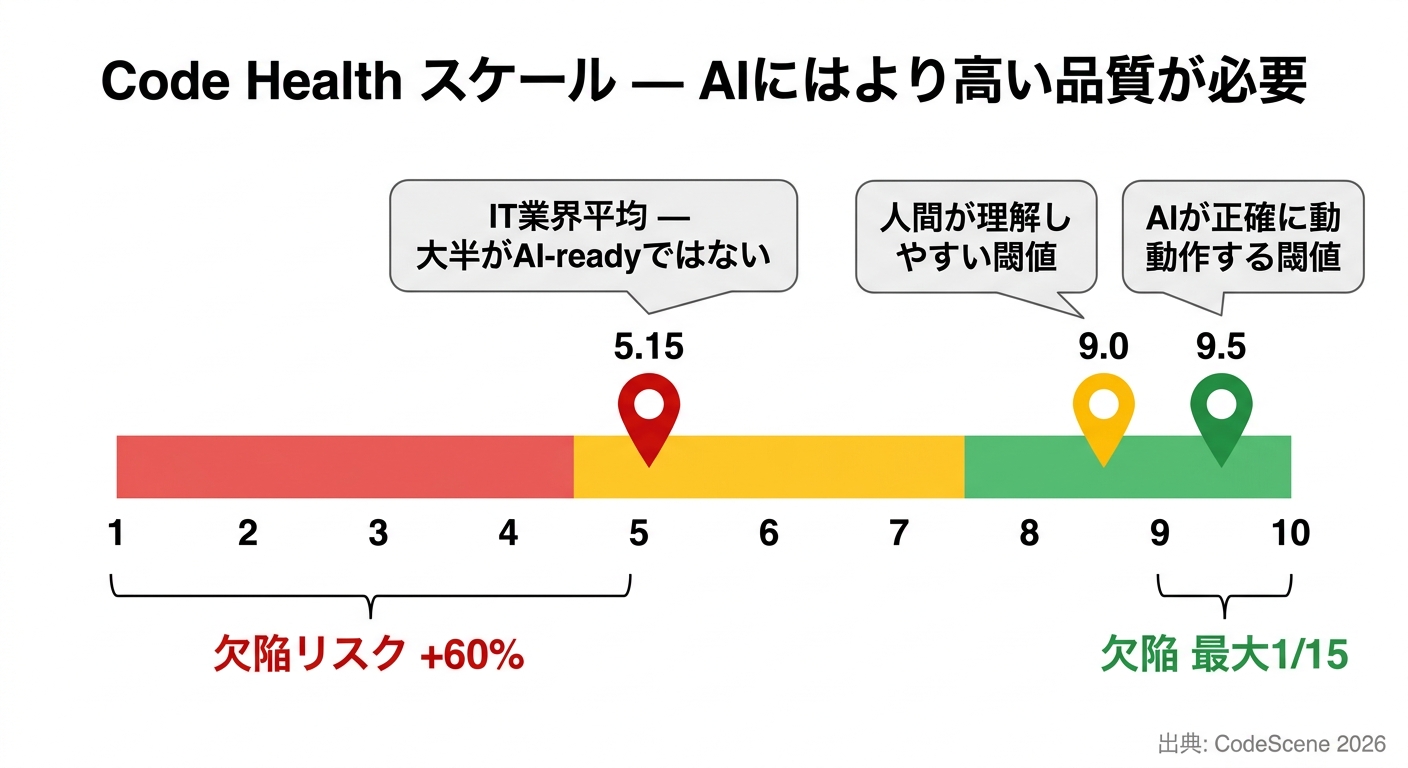
CodeSceneの研究はこれをさらに定量化しました。Code Healthが低いプロジェクトでAIを使用した場合、欠陥リスクが30%以上増加します(V1データ)。最新のV2ではさらに60%増という数字も出ています。また5,000のPythonリポジトリを6種類のLLMで分析したFORGE 2026の査読済み論文(Borg & Tornhill)でも、全LLMで p < 0.001 という有意な相関が確認されています。IT業界全体のCode Health平均は5.15/10。大半のプロジェクトが、AIを有効活用できる状態にありません。
対策——「設計を先に渡す」
「バイブコーディングをやめろ」という結論にはなりません。AIの生成速度は本物で、うまく使えば開発体験は確かに変わります。問題は、「設計のない状態でAIに書かせる」という運用にあります。
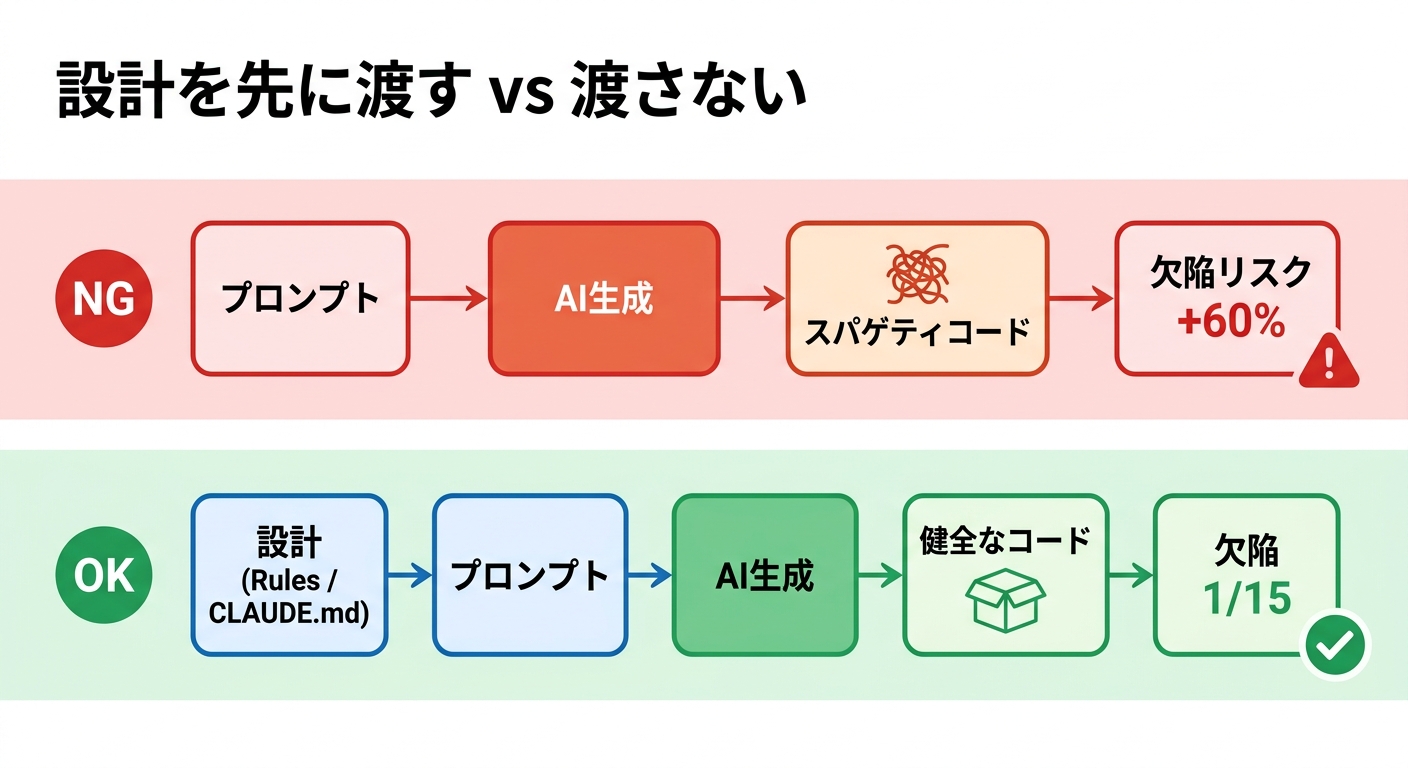
CodeSceneのホワイトペーパー(V2)が提示する基準は具体的です。Code Health 9.5以上を維持しているプロジェクトでは、AIが正確に動作しやすく、欠陥リスクが大きく下がります。逆に言えば、既存コードのCode Healthが低い状態でAIにコードを追加させると、問題は増幅していく一方になります。
実践的なアプローチとして、CodeScene MCPがOSSとして公開済みです。Claude Codeから直接Code Healthを計測し、リファクタリング対象の特定とその実施をエージェントループに組み込めます。CodeSceneの事例データによれば、MCP経由でリファクタリングを実施した場合の効果は通常の2〜5倍という報告があります。Code Redの研究は、Code Healthが高いプロジェクトでは欠陥が最大15分の1、開発速度が最大9倍になるという長期データも示しています。
個人的には「Code Health 9.5以上」というラインを目標として記憶しておくことに価値があると思っています。「設計がないとAIに書かせてはいけない」という漠然とした原則より、数値的な閾値のほうが運用に落とし込みやすいです。ハーネス設計(Rules/Hooks/Skills)を活用して品質を「強制」する具体的な手法については、別稿で改めて解説します。
まとめ
AIの速度と人間の設計は、組み合わせて初めて機能します。
バイブコーディングが問題なのは「速すぎる」からではなく、「設計を省略したまま速くなれる」という誤解を与えるからです。CodeRabbitのデータが示す1.7倍の問題密度、Politowskiらが実証した「2つのアンチパターンで理解能力が崩壊する」という閾値効果、CodeSceneが示すCode Health劣化と欠陥リスクの相関——これらが一本の線でつながります。
「設計をAIに渡してからバイブコーディングしろ」。これが現時点での最もシンプルな処方箋だと考えています。きれいなコードに対してAIは精度よく動きます。その逆は、今見てきたとおりです。
シリーズ全3回
- 第1回:バイブコーディングとコード品質の実態(この記事)
- 第2回:Code Health 9.5がAIの精度を決める
- 第3回:CodeScene MCP × refactor-health 実践ガイド(近日公開)
関連記事
Sources
- CodeRabbit: State of AI vs Human Code Generation Report | CodeRabbit
- A Large Scale Empirical Study of Spaghetti Code and Blob Anti-patterns | Politowski et al. / arXiv
- AI-Ready Code: How Code Health Determines AI Performance (Whitepaper V2) | CodeScene
- Code for Machines, Not Just Humans (FORGE 2026) | Borg & Tornhill / arXiv
- Making Legacy Code AI-Ready: Benchmarks on Agentic Refactoring | CodeScene
- Coding on Copilot: 2025 AI Code Quality Report | GitClear